FIABILIDAD (V): COMPARACIÓN (NO PARAMÉTRICA) DE
Anuncio
: COMPARACIÓN (NO PARAMÉTRICA) DE")
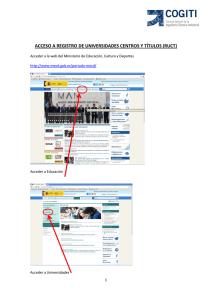
Comparación no paramétrica de muestras FIABILIDAD (V): COMPARACIÓN (NO PARAMÉTRICA) DE MUESTRAS Autores: Ángel A. Juan Pérez ([email protected]), Rafael García Martín ([email protected]). RELACIÓN CON OTROS MATH-BLOCS__________________________________ Este math-block forma parte de una serie de 8 documentos relacionados todos ellos con la Fiabilidad de componentes desde un punto de vista estadístico: • • • • • • • • Conceptos Básicos (I). Identificación y descripción gráfica de los datos (II). Análisis paramétrico de los tiempos de fallo (III). Análisis no paramétrico de los tiempos de fallo (IV). Comparación no paramétrica de muestras (V). Tests de vida acelerada (VI). Modelos de regresión para observaciones censuradas (VII). Análisis Probit (Éxito / fracaso) (VIII). ESQUEMA DE CONTENIDOS___________________________________________ Comparación de 2 grupos Fiabilidad (V): Comparación (no paramétrica) de muestras Comparación de n grupos (n > 2) Ejemplo comparación grupos (Statistica) Proyecto e-Math Financiado por la Secretaría de Estado de Educación y Universidades (MECD) 1 Comparación no paramétrica de muestras INTRODUCCIÓN_____________________________________________________ A menudo, puede resultar conveniente usar métodos no paramétricos para comparar los tiempos de fallo procedentes de diferentes muestras. Así, por ejemplo, en el caso de los portátiles (visto en el capítulo anterior), podríamos estar interesados en comparar los tiempos de supervivencia de los tres grupos determinados según el taller de reparación al que corresponde cada observación. A priori, cuando los tiempos de fallo no se distribuyan según una normal, podría pensarse en utilizar los métodos no paramétricos clásicos, tales como los métodos Wilcoxon o Mann-Whitney para comparar dos muestras, o el Kruskal-Wallis para varias muestras. Sin embargo, estos métodos tradicionales no son válidos cuando las muestras contienen observaciones censuradas, debiendo recurrir en tales casos a alguno de los métodos no paramétricos específicos que se enuncian en el siguiente cuadro: MÉTODOS PARA COMPARAR GRUPOS CON OBSERVACIONES CENSURADAS Comparación de 2 grupos Comparación de múltiples grupos Wilcoxon-Gehan Cox-Mantel F-Cox Log-rank Wilcoxon-Peto Wilcoxon-Gehan generalizado Cox-Mantel generalizado La mayoría de estos métodos proporcionarán valores de una v.a. Z que sigue una distribución normal tipificada (i.e., una N(0,1)); dichos valores se usarán para hacer un contraste de hipótesis sobre la similitud o no de los grupos. A fin de que los resultados sean estadísticamente fiables, será necesario disponer de muestras suficientemente numerosas. Es importante observar además que, cuando se quieran comparar dos o más grupos resulta fundamental examinar primero la proporción de observaciones censuradas en cada uno de ellos, dado que si dicha proporción difiere de forma notable según el grupo, los resultados podrían resultar bastante sesgados. Si bien no hay un criterio general sobre qué método es mejor, a la hora de comparar dos grupos, si las muestras provienen de una población con distribución Exponencial o Weibull, los métodos CoxMantel y log-rank parecen ofrecer resultados más fiables. El test Wilcoxon-Gehan para múltiples grupos es una generalización de los métodos Wilcoxon-Gehan. De hecho, cuando se utiliza este test con sólo dos grupos de muestras, los resultados que se obtienen son los mismos que con el Wilcoxon-Gehan. Proyecto e-Math Financiado por la Secretaría de Estado de Educación y Universidades (MECD) 2 Comparación no paramétrica de muestras COMPARACIÓN DE 2 GRUPOS___________________________________ Supongamos que se dispone de n1 y n2 observaciones pertenecientes a los grupos 1 y 2: {(t1i, δ1i)}ni=11 y donde: 0 δ1i = 1 si hay censura en t 1i si hay fallo en t 1i y {(t2j, δ2 j)}nj=21 0 δ2j = 1 si hay censura en t 2j si hay fallo en t 2j Sea d = “número total de fallos en ambas muestras”, (i) Se unen las observaciones procedentes de ambos grupos, y se consideran m instantes (ordenados) en los cuales se haya producido al menos 1 fallo: t1 < t 2 < ... < t m con m ≤ d ≤ n1 + n2 (ii) En cada uno de los instantes anteriores, ti , 1 ≤ i ≤ m , se podrán resumir los datos en una tabla 2x2: Nº de observ. del grupo 1 que estaban en riesgo justo antes del instante ti: n’ = n + d MUESTRA 1 2 Total Fallo (d) d1i d2i di Nº de observ. del grupo 1 que han fallado justo en el instante ti ESTADO En Riesgo (d + n) n’1i n’2i n’i Supervivientes (n) n1i n2i ni Nº de observ. del grupo 1 supervivientes tras el instante ti Tendremos así que la hipótesis nula H0: probabilidad de supervivencia es la misma en ambas muestras implica la independencia de las categorías “muestra” y “estado” de la tabla 2x2 anterior. Por tanto, bajo la hipótesis nula, el valor esperado de d1i (nº de fallos del grupo 1 en el instante ti) será: E[d1i/H0] ≡ E0[d1i] = n’1i * di / n’i Usando las propiedades de la distribución Hipergeométrica, también se tiene que: Var[d1i/H0] ≡ Var0[d1i] = [n’1i * n’2i * ni * di] / [n’i2 * (n’i – 1)] Proyecto e-Math Financiado por la Secretaría de Estado de Educación y Universidades (MECD) 3 Comparación no paramétrica de muestras Por su parte, es posible representar la evidencia en contra de la hipótesis nula con el siguiente estadístico de contraste, el cual es una suma ponderada de las diferencias entre el número de fallos observados y el número de fallos esperados en el grupo 1: m ∑ wi [d1i − E0 [d1i ]] θ= i =1 donde wi es el “peso” asociado al instante ti. Se puede demostrar que el estadístico anterior sigue una distribución normal. Calculemos su media y varianza: Bajo H0, se cumplirá: E[θ/H0] ≡ E0[θ] = 0 Var[θ/H0] ≡ Var0[θ] = Σ wi2 Var0[d1i] = Σ [wi2 * n’1i * n’2i * ni * di] / [n’i2 * (n’i – 1)] Estandarizando θ se obtendrá un estadístico de contraste que se distribuye según una normal tipificada, i.e.: Z= θ Var0 (θ) ≈ N(0,1) o, equivalentemente, se tiene que Z2 sigue una Chi-cuadrado con 1 grado de libertad: Z2 = θ2 ≈ χ12 Var0 (θ) 1) Tomando wi = n’i estaremos en el método Wilcoxon-Gehan, el cual se reduce al test clásico de Wilcoxon cuando no hay observaciones censuradas. 2) Tomando wi = 1 estaremos en el método Log-rank o Cox-Mantel. 3) Tomando wi = √n’i estaremos en el método Tarone-Ware. 4) Tomando wi = estimación de S(t) en t = ti estaremos en el método Wilcoxon-Peto. Observaciones: • El test Wilcoxon-Gehan pone más peso en las observaciones iniciales, por tanto es más “sensible” a la hora de detectar la existencia de diferencias a corto plazo entre grupos. • El test Log-rank pone el mismo peso en todas las observaciones, por lo tanto resulta más “sensible” a la hora de detectar la existencia de diferencias a largo plazo entre grupos. • Debido a la forma en que los tests se formulan (los términos del sumatorio en la expresión de θ no están elevados al cuadrado), éstos sólo serán “potentes” cuando la tasa de riesgo de un grupo siempre sea menor que la del otro (i.e., al representar sus respectivas funciones tasa de riesgo, éstas no se crucen). En caso contrario, podría ocurrir que algunos términos del sumatorio anterior positivos y otros negativos, cancelándose mutuamente. Proyecto e-Math Financiado por la Secretaría de Estado de Educación y Universidades (MECD) 4 Comparación no paramétrica de muestras COMPARACIÓN DE VARIOS GRUPOS___________________________________ Los métodos anteriores para comparar 2 grupos se pueden generalizar al caso de k grupos: Se ordenan los tiempos de fallo: t 1 < t 2 < ... < t m con m ≤ d ≤ n1 + ... + n k y para cada ti se construye la siguiente tabla 2xk: Muestra 1 . . . k Total Fallo (d) d1i . . . dki di ESTADO En Riesgo (d + n) n’1i . . . n’ki n’i Supervivientes (n) n1i . . . nki ni Por tanto, bajo la hipótesis nula, el valor esperado de dji (nº de fallos del grupo j-ésimo en el instante ti) será: E[dji/H0] ≡ E0[dji] = n’ji * di / n’i y los componentes de la matriz de covarianza serán: [ ] Var0 d ji = n' ji (n'i −n' ji ) ⋅ di ⋅ ni n'i2 (n'i −1) y [ ] Cov 0 d ji , dli = −n' ji ⋅n'li ⋅di ⋅ ni n'i2 (n'i −1) La evidencia contra H0 vendrá representada por el estadístico de contraste: m θ= ∑ wiDi i =1 d1i − E 0 [d1i ] . donde wi es el peso asociado a las observaciones en el instante ti , y Di = . . dki − E 0 [dki ] A efectos prácticos, se usará el estadístico de contraste χ2 construido a partir de θ: −1 χ 2 = θ′ ⋅ Vw ⋅θ el cual sigue una distribución χ2 con (k-1) grados de libertad. En la expresión anterior, Vw = w2 V , siendo w el vector de pesos wi . Tomando wi = ni se obtiene el método de Wilcoxon-Gehan generalizado mientras que tomando wi = 1 tendremos el test de Log-rank o Cox-Mantel generalizado. Proyecto e-Math Financiado por la Secretaría de Estado de Educación y Universidades (MECD) 5 Comparación no paramétrica de muestras EJEMPLO COMPARACIÓN DE GRUPOS_________________________________ Usando el programa STATISTICA y, nuevamente, el ejemplo de los portátiles (considerando tres grupos, uno por cada taller de reparación) se mostrará cómo es posible aplicar en la práctica los métodos anteriores de comparación: Entrada de datos (input): Seleccionamos la opción Comparing multiple samples en el menú inicial del módulo. Pulsar sobre el botón Variables para seleccionar los tiempos de fallo, el indicador de censura, y la variable que determina los grupos (Taller ). Comprobar que la opción Code for censored responses variables censuradas. muestra los códigos correctos de las Dentro de la opción Codes (for groups) , pulsar sobre el botón All : Proyecto e-Math Financiado por la Secretaría de Estado de Educación y Universidades (MECD) 6 Comparación no paramétrica de muestras Salida de datos (output): El programa mostrará los siguientes resultados: Notar que el test Chi-Cuadrado es casi significativo en este caso (p-valor = 0,05672), por lo que estaríamos tentados de rechazar la hipótesis nula (no hay diferencias importantes entre los tres grupos) en favor de la hipótesis alternativa (la duración de los portátiles depende del taller donde fueron arreglados). A fin de poder apreciar mejor estas más que posibles diferencias, se podrían representar en un mismo gráfico las funciones de supervivencia de cada grupo. Para ello se debe pulsar sobre la opción Cumul. prop. surviving by group (Kaplan-Meier) : Cumulative Proportion Surviving (Kaplan-Meier) Complete Censored 1,0 Cumulative Proportion Surviving 0,9 0,8 0,7 0,6 0,5 0,4 A 0,3 0,2 B 0 200 400 600 800 1000 1200 1400 1600 1800 2000 C Time Claramente, la función de supervivencia correspondiente al taller C muestra una disminución inicial menos acusada que la del resto de talleres. Por tanto, deberíamos concluir que los portátiles reparados en el taller C tienen una mayor probabilidad de “sobrevivir”, en especial durante los primeros 100 días críticos posteriores a la reparación. Proyecto e-Math Financiado por la Secretaría de Estado de Educación y Universidades (MECD) 7 Comparación no paramétrica de muestras Pulsando sobre el botón Percent surviving by group se obtendrán las tablas de supervivencia para cada grupo: Entrada de datos (input): Ahora que ya se ha comprobado que no todos los grupos son similares, sería conveniente comparar dos de ellos, el A y el C, para comprobar nuestra observación anterior de que el taller C parece tener unos resultados diferentes a los del resto, en particular a los del taller A. Para ello, se deberá seleccionar la opción Comparing two samples en el menú inicial del módulo. Pulsando sobre el botón Variables indicaremos las variables que contienen los tiempos de fallo, el indicador de censura, y los grupos (Taller ). Comprobar que la opción Code for censored responses muestra los códigos correctos de las variables censuradas, y seleccionar los códigos de los grupos: Proyecto e-Math Financiado por la Secretaría de Estado de Educación y Universidades (MECD) 8 Comparación no paramétrica de muestras Salida de datos (output): a continuación se muestran los resultados: Seleccionando cada uno de los métodos se irán obteniendo, entre otras, las siguientes ventanas: Observar que, en este ejemplo, algunos de los tests dan p-valores cercanos al 0,05 (como el Wilcoxon-Gehan), mientras que otros no son estadísticamente significativos (como el F-Cox). Por tanto, se podría concluir, aunque sin excesiva seguridad, que los resultados obtenidos en ambos talleres son diferentes, proporcionando el taller C mayor fiabilidad en las reparaciones de portátiles. Proyecto e-Math Financiado por la Secretaría de Estado de Educación y Universidades (MECD) 9 Comparación no paramétrica de muestras BIBLIOGRAFÍA______________________________________________________ [1]. [2]. [3]. [4]. [5]. [6]. [7]. [8]. [9]. [10]. Conover, W.J. (1980). Practical nonparametric statistics. Wiley. New York. D’Agostino, R.B. y Stephens, M.A. (eds.) (1986). Goodness-of-fit techniques. Marcel Dekker. New York. Gibbons,J.D. (1971). Nonparametric Statistical Inference. McGraw Hill. San Francisco. Kendall, M.G. y Gibbons, J.D. (1991). Rank Correlation Methods (5a. edición). Griffin: Londres. Koopmans, L. (1987) Introduction to Contemporary Statistical Methods (2a. edición) PWS Publishers. Lehmann, E.L. (1975). Nonparametrics: Statistical Methods Based on Ranks. McGraw Hill. San Francisco. Leach, C. (1989). Fundamentos de estadística: Enfoque no paramétrico. Limusa. México, D. F. Puri, M.L. y Sen, P.K. (1971). Nonparametric methods in multivariate analysis. Wiley. Nueva York. Randles, R.H. y Wolfe, D.A. (1979). Introduction to the Theory of Nonparametric Statistics. Wiley. Nueva York. Silvermann, B.W. (1986). Density Estimation. Chapman and Hall: Londres. ENLACES___________________________________________________________ [W1] http://www.statsoft.com/textbook/stathome.html Libro electrónico de Statsoft.Inc (creadores del programa Statistica) [W2] http://software.biostat.washington.edu/~rossini/courses/intro-nonpar/text/ Libro electrónico editado por el profesor Rossini. Proyecto e-Math Financiado por la Secretaría de Estado de Educación y Universidades (MECD) 10