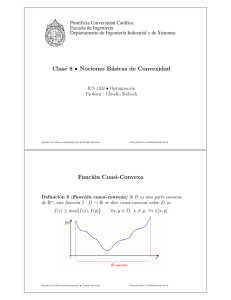
Métodos de optimización para modelos predictivos
basados en datos
diseño + construcción + ejemplos
Curso: Modelos matemáticos y numéricos
Instructor: José Luis Morales
Sesión de posters.
Fecha: viernes 27 de noviembre
Hora: 10:00-14:00
Lugar: Pasillo de Rectorı́a
Resumen
Los modelos predictivos basados en conjuntos muy grandes de datos juegan un papel crucial en
diversas aplicaciones. Su diseño y construcción se pueden formular como problemas de optimización
minimizar
p
sujeta a
f (p; D),
D = {(xi , yi ),
i = 1, . . . , N }
c(p; D) ≥ 0,
en donde el vector n−dimensional p representa a los parámetros del modelo m(p, x) y D al conjunto
de datos; f es una medida del error total entre las predicciones del modelo ȳ = m(p, x) y las
observaciones y. Tı́picamente
N
X
f (p; D) =
E(ȳi − yi ).
i=1
La función f es convexa y dos veces continuamente diferenciable. Sin embargo, es común agregar
a f un término de regularización
f (p; D) + r(p),
r es convexa pero NO necesariamente diferenciable. Otra dificultad conocida es que N , el número
de datos, supera en forma abrumadora a n, el número de parámetros. Por lo tanto, los métodos
convencionales en optimización no pueden usarse directamente.
Los estudiantes del curso presentarán resultados obtenidos con los siguientes métodos: a) máquinas de soporte vectorial; b) regresión logı́stica regularizada en tres variantes; c) gradiente estocástico.
1
 0
0